In a world where the internet is flooded with deceitful sources spreading misinformation, it’s reassuring to know that there is one area that upholds honesty and integrity: the peer-review process for scholarly publications.
When scientists, doctors, and experts in various fields submit their research articles, they undergo a rigorous review by other experts in the same field. These reviewers meticulously examine the accuracy, accountability, and quality of the papers. If a paper doesn’t meet the publication’s high standards, it is either returned with recommended adjustments or rejected. However, if it successfully passes this robust and challenging review, it is ready for publication.
Peer review has a long history, with the Philosophical Transactions of the Royal Society being the first to adopt this formal procedure in the 17th century. Today, an estimated 5.14 million peer-reviewed articles are published annually, with over 100 million hours dedicated to these reviews.
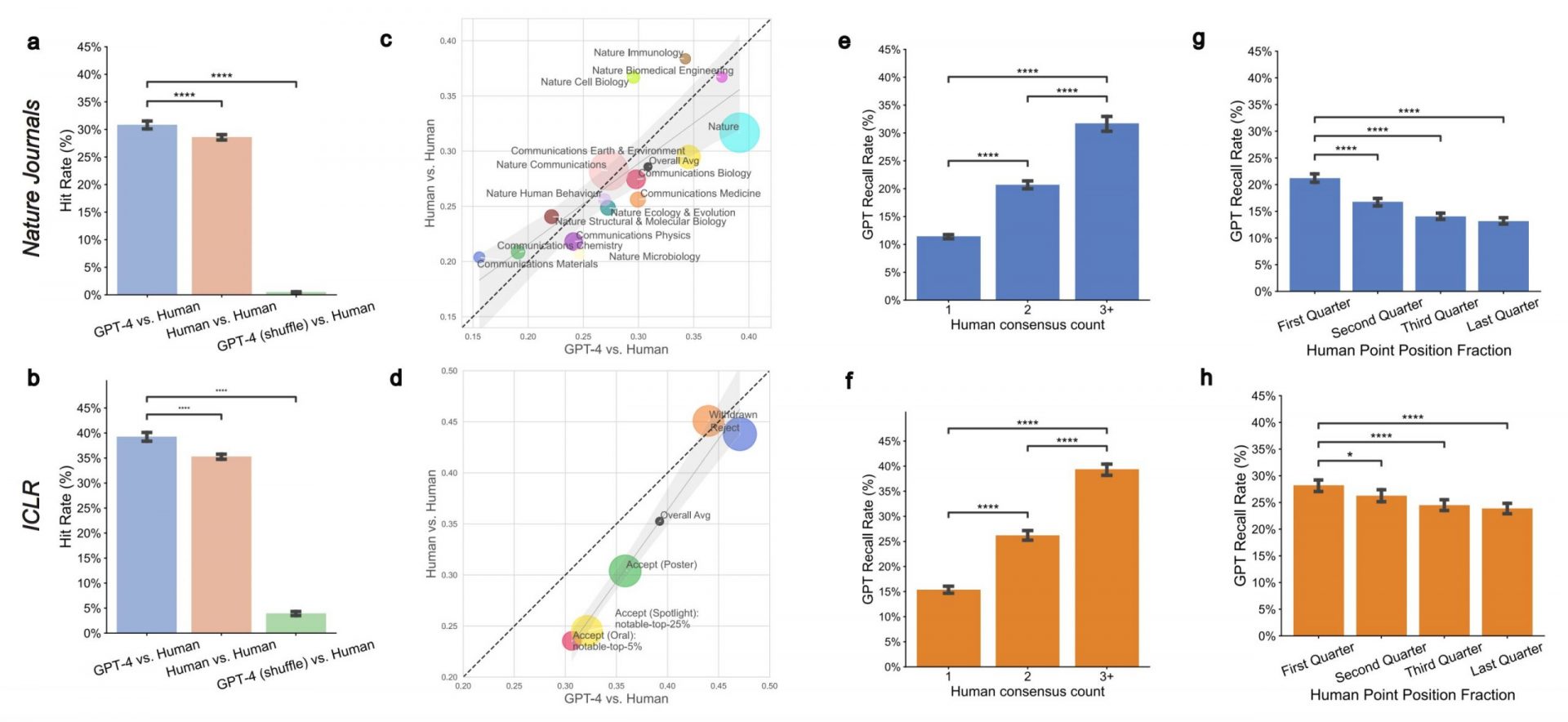
Considering the lengthy wait times, high costs, and difficulty in finding qualified reviewers, researchers at Stanford University explored how large language models (LLMs) could assist in the review process. They found that LLMs could be highly beneficial for publications and authors, as high-quality peer reviews are becoming increasingly difficult to obtain.
To test their theory, the researchers compared reviewer feedback from human experts with reviews generated by GPT-4, a large language model. They discovered that there was a significant overlap of 31% to 39% in the points raised by both human and machine-generated reviews. In fact, on weaker submissions that were rejected, GPT-4 performed even better, overlapping with human scorers 44% of the time. Authors of these papers also found the LLM feedback to be helpful, with more than half describing it as such.
However, the report emphasized that LLMs are not a replacement for human oversight. They acknowledged some limitations, such as vague reviews, failure to provide specific technical improvements, and a lack of in-depth critique of model architecture and design. Expert human feedback remains crucial for rigorous scientific evaluation.
In conclusion, while LLMs can complement human feedback, they cannot substitute the thoughtful insights provided by domain experts. The study’s findings suggest that incorporating LLMs into the review process can be particularly beneficial for guiding authors who need substantial revisions. By addressing concerns earlier in the scientific process, these papers and the science they present can be improved.